
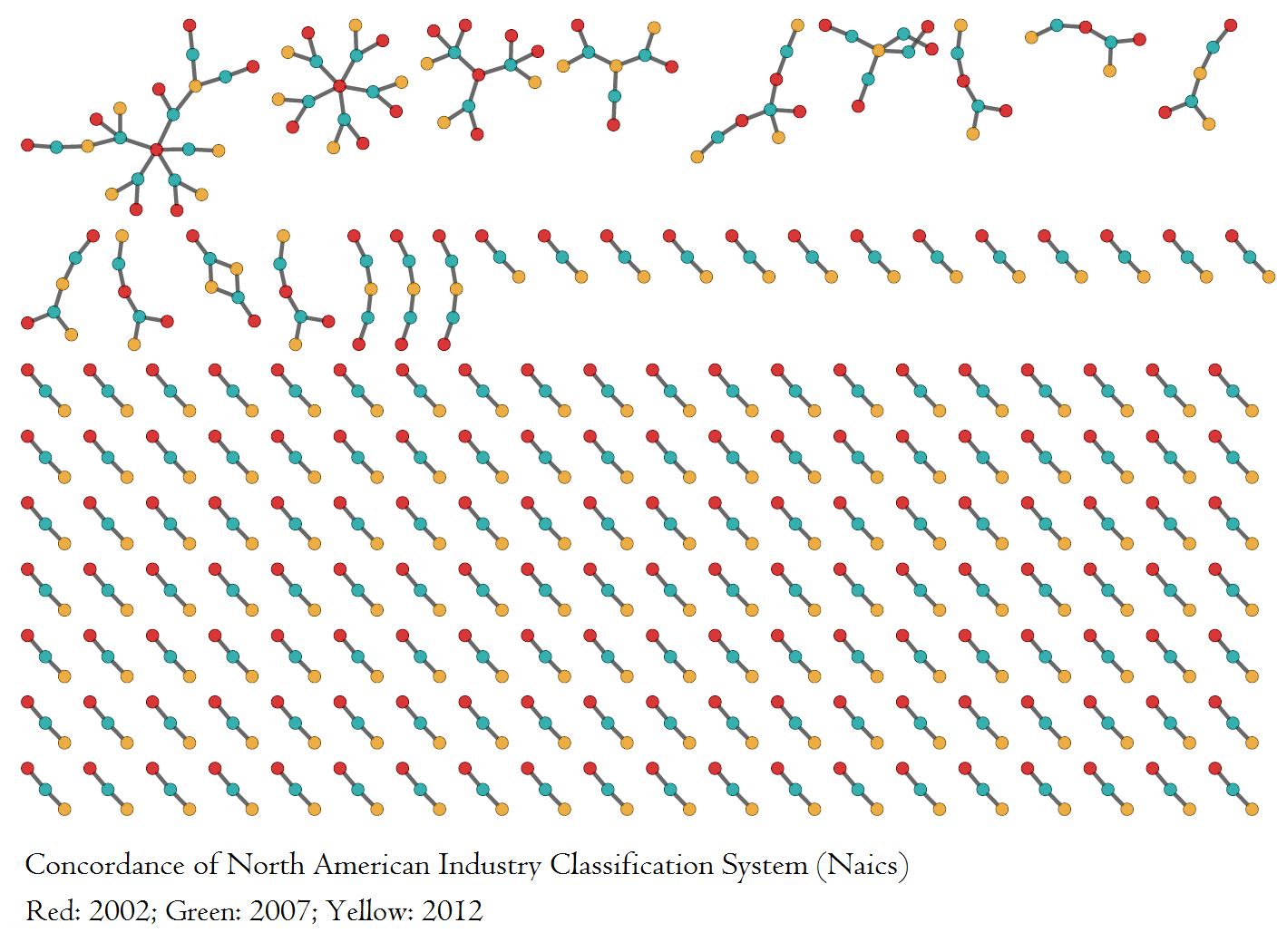
A frequent problem in research is the harmonization of data to a common classification, whether that is in terms of — to name a few examples — industries, commodities, occupations, or geographical areas. Statistical offices often provide concordance tables, to match data through time or with different classification, but these concordance tables alone are often not sufficient to define a clear methodology on how the matching should be performed. In fact, the concordance tables have, in numerous occasions, a many-to-many mapping of classifications. The issue is exacerbated when two or more concordance tables are concatenated.
In this Jupyter notebook, I discuss a network-based abstraction of this problem and propose, as a general solution, a method that identifies the network components (or the network communities) to make data converge to a new classification. The method simplifies the issue and reduces greatly conversion errors.

